Prepared By: Allan Bartleywood, TxMQ Subject Matter Expert, Senior Consultant and Architect, MQ
Project Description
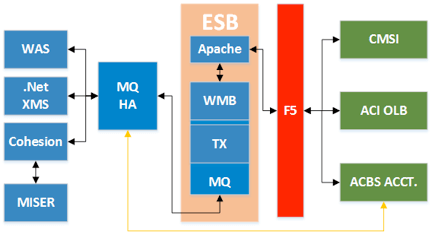
“Regional Bank A” has a technical infrastructure supporting application integration through the use of an Enterprise Service Bus (“ESB”) serving as mediator between application endpoints and other backend systems. This tier consists of several of the IBM WebSphere products including WebSphere MQ, WTX and Message Broker.
Working together, these products provide data transformation and routing so that data exchange occurs in native-application formats in near-real-time conditions, with data transformation occurring primarily in WebSphere Message Broker with connectivity to WTX for EDI format map transformation following pre-packaged EDI standards. Message flows are created by “Regional Bank A” projects for defining routing and data delivery rules for new or changed applications.
This environment requires regular, ongoing development support as well as quarterly software maintenance for regular applying of software patches related to Linux and Microsoft Windows operating-system software.
Overview of Findings
The recent reviews conducted by the performing consultant include the infrastructure components indicated in subsection
1. In review of infrastructure best practices for the financial services industry, the following findings were noted:
2.1 Monitoring Optimization for Performance Management & Capacity Planning
Generally speaking, there is significant opportunity to improve the monitoring approach to attain monitoring and management objectives in a way that is considerably more cost-effective than what is presently being practiced.
2.2 Infrastructure Security Strategy Following Pre-Regulatory Standards
Of notice with regard to companies operating in the financial services industry, the security-regulatory environment has changed significantly in the past 10 years. The reported number of breaches in 2012 was astoundingly high at more than 1,000 occurrences. With such voracity of hacking efforts focused on financial services companies, it is imperative that security vulnerabilities be addressed as a priority, and that highest standards and practices are implemented to ensure against such attacks.
The areas identified for improvement are reviewed in the Security subsection below. There are several major components that must be addressed for “Regional Bank A” in the very near future.
2.3 Standards & Best Practices
Within the WebSphere product portfolio, there are several IBM standards and recommendations for installation, configuration and performance tuning for the infrastructure stack. In particular, the standards around the middleware-messaging components (“MQ”) were found to be inconsistent and in need of configuration management. Additionally, Java applications brokered on WebSphere Application Server were found to be running on Java Virtual Machines (“JVM”) that were not configured according to best practices across the board.
This type of situation generally occurs when multiple people are involved with installation and configuration activities, without the guidance and oversight of a middleware architect who would generally ensure that such standards are applied and documented across the topology. More observations and recommendations are shared in the subsections below.
2.4 Software Distribution and Deployment Automation
A review of “Regional Bank A’s” application-release process – i.e., how changes are made to the middleware environment – found the current process to be very informal. Because the environment is small, the implementation of automation at this time will provide significant process improvement and thus positioning “Regional Bank A” for growth. Without this automation, the ongoing cost of development efforts will continue to increase without accompanying levels of development output, due to increasing the complexity of changes and the effort required to manage so many moving parts. This area has been identified as a strategic area of investment for “Regional Bank A” organization and application-growth enablement.
Monitoring Observations
For infrastructures that include an ESB, the standard monitoring approach should encompass the entire end-to-end view of the production technical components at both base server level and application level. This will capture end-to-end business transaction success or failure to complete, providing the ability to identify where specific failures are occurring. The approach should also include the ability to capture relevant data used for planning capacity, to understand and characterizing the behavior of the end-to-end system, and provide information used for middleware performance tuning.
“Regional Bank A’s” monitoring was found to be somewhat component focused with primary focus at the hardware level. Some stats are being captured at all levels, but not in a consistent way in terms of granularity or storage of information that would make the data useful for analysis.
Examples of what is being monitored today include:
- Real-time usage by PID using TOP
- Some collection of server stats in the O/S
The areas of suggested improvements include:
- At Operating-System Level – Capture state and usage of each host (physical or virtual); if running virtually, it is critical that the state is known for the physical mapping to virtual.
- At Application-Monitor Level – Critically available information depends on knowing the state (up/down/hung) of the application stack.
- At Transaction-Monitor Level – Service management is dependent on knowing three things:
Number of transactions completed in the SLA
How many failed?
How many were delayed?
- It is also useful to know the service-response times, and stats concerning known bottlenecks such as page-load time, JVM utilization and metrics such as user-response time and invocation stats.
- Proactive Monitoring – The plan for capacity high/low thresholds needs to be defined and regularly evaluated in response to events and situations where thresholds are exceeded but before an outage has actually occurred.
- Performance Management & Capacity Planning – For effective cost management of this infrastructure, the initial implementation for the environments may be a subset of full capacity, with the intent to add to the environment as application growth occurs. To accompany this strategy, monitoring data must be captured and stored (using a data warehouse) for trending, tuning, and capacity-planning purposes.
- “Regional Bank A” is currently not storing monitoring data for any significant length of time. Additionally, a data-maintenance strategy and centralized group to analyze and review performance data on a regular basis should be incorporated into the growth strategy.
- Security – With recent regulatory changes, all unauthorized access of data must be reported. In order to comply, IT must have a logging strategy and log retention of security events expanded into this tier of infrastructure where application messages are currently passing through and security could be compromised.
Security Observations
The IT Security components involved with this particular infrastructure include:
- SSL Certificate Management
- Operating System Level Security
- Message Security
- Secure Connection Management
- General Application Level Security
- Period of Access.
4.1 SSL Certificate Management Observations
There does not appear to be a centralized authority to govern the way certificates are issued, installed and managed for “Regional Bank A.” General process around certificate management includes: certificate issuance (i.e. purchase and download), installation/configuration by administrator, tracking and renewal of expired certs, secure and re-issuance process to avoid multiple use and/or counterfeit certs.
It was observed that SSL certificates were found in various directories on the server. Moving forward, the recommendation is that certificates be stored immediately upon receipt in a secure Key Store. Certificate files should then be deleted from all other locations and system files.
Message Security Observations
- MQM group on UNIX should not contain any members other than system IDs
- All application IDs and people-user IDs should be placed in other group IDs that are specifically configured for their access and usage alone
- Root should never be a member of the MQM group
- “Minimum privilege” groups should be created and used for “read” access and configured in MQ Security to the objects required for usage
- In outsourced IT environments, support groups should have minimum access privileges to prevent outages related to accidental operational support activity
- Best practice is to use an MQ Change Request ID to access the MQM ID via the Unix “sudo” command for applying any changes or maintenance to MQ objects. This approach is also commonly referred to as granting access using a “Firecall” ID for specific instances when access is actually required while fully logging all activities performed by the ID during the period of access.
4.2 Application Connectivity For Message Queuing
MQ Client connectivity provides access to applications running remotely (on the application servers) with the ability to put and get from MQ queues. During the review, it was suggested that all consumers of the MQ environment should use only a single Client Channel definition. This is not recommended and falls outside of best practice for the following reasons:
- Lack of application association on each individual connect and disconnect.
- Security Authorization Records become extremely difficult to manage (for example, identifying who had access when an actual breach occurred).
- Operational support resolution will require longer and possibly multiple outages to identify root cause of connection issues (applications that are long running).
- Heightened risk of outages to larger groups of users: When a single consumer encounters a connection issue, there is higher risk that all consumers will be “kicked off” while a channel bounce is done to resolve connectivity issues.
4.3 Application Server Management Observations include:
- WAS processes running on the servers using Root ID – this is a major security violation in financial-services industry.
- A “wasadmin” Unix non-expiry ID should be used for the running of all WAS processes.
- Access to the “wasadmin” ID should be managed operationally, granting a “firecall ID” in the same manner as outlined above for access to the MQM ID for changes and support.
4.4 Middleware Security Using “sudo”
In UNIX, the sudo command is enabled to control access via groups or user ids. Sudo can be focused to just explicit commands and options, and should always have full audit enabled for logging of user activity.
Standards and Best Practices
Throughout all aspects of the review, there appeared to be a disconnect between the “Regional Bank A” teams and the managed-services provider teams that were implementing and providing first-level support for both WAS and MQ. This disconnect can be resolved by:
1. Defining a single set of Standards, Practices and Guidelines issued by “Regional Bank A” that require unilateral adherence by MSP as well as by internal teams;
2. Setting up regular reviews of such policies and standards on a quarterly or project-by-project basis.
Architecture standards should exist in an ESB Architecture Guide, including the security policies for connectivity and access.
Other concerns and best practice observations are as follows:
5.1 WebSphere MQ
The key resource manager for all incoming and outgoing data for the ESB is controlled by the WebSphere MQ Queue Managers. Queue Manager base definitions were not found to be consistent and varied from default settings for what appear to be arbitrary reasons with high levels of inconsistencies across system and application-object configurations. These configurations do require some level of cleanup and maintenance for best practices environment management.
Use of NFS within the Linux/VM environment could be a regular source of compromise regarding high availability. When all other attempts have failed to resolve an NFS issue, the last resort is to bounce the NAS server, which results in immediate outage of all NAS services to all system consumers.
Instead, moving to a direct-storage product like Veritas™ Volume Manager is a cost-effective and reliable practice for ensuring high availability across clusters.
Also, consideration should be given to implementing MQ AMS (Advanced Message Security) to ensure compliance with PCI-DSS standards. This product is used to enforce encryption of messages at rest in the MQ queues to ensure that any and all access to queues will not provide access to readable message content. AMS in conjunction with MQ Security restriction of access will go far in preventing unauthorized access within this tier of the overall application architecture.
5.2 WebSphere Application Server
Several concerns were noted with the WAS implementation supporting “Regional Bank A’s” Java applications:
- Operating systems not tuned according to minimum IBM standards
- JVMs not tuned
- Environment variables not being set
- Single application/JVM profiles used on the assumption of securing data segregation of application data
Software Configuration Management and Deployment Automation
When changes are introduced into the ESB for software maintenance, when new applications are introduced, or when changes are made to enable better performance or transaction growth, a key area of concern for problem reduction and ongoing stability is to look at how such changes are introduced, tested and validated prior to deployment into the production environment where business transactions are running – the environment where interruption may involve loss of revenue for “Regional Bank A.”
Improvements in the following areas could be explored further for future engagement scope:
6.1 Software Configuration Management
How the application code is stored and version controlled is critical in the practice of software-configuration management. In addition, how the code is migrated to production is an area of extreme scrutiny for most financial-services companies. PCI compliance generally requires the demonstration of secure and formal access control around all source code and code-migration activities to production systems to ensure against introduction of rogue code or malware on financial systems.
Generally speaking, this is an area where best practice is quite mature as related to CMM and pre-Y2K efforts to manage the deployment of massive amounts of code change without business interruption – more from a stability and availability-management perspective.
Since most problems are related to changes made within the environment, most financial-services IT organizations are quite strict and process-oriented, with significant automation around the software-development life cycle (“SDLC”) to ensure against business disruption due to release testing in an environment that is not managed and controlled with the same configuration as production.
At “Regional Bank A,” application deployments are a highly manual effort with some utilization of homegrown scripts, which are subject to human error, inconsistent configurations, and are time-consuming to manage and support.
Key concerns with the current software-distribution strategy include:
- High degree of error and inconsistencies
- High labor cost in deployment process
- High risk of losing skills relating to custom-deployment process and administrator knowledge of each application’s configuration and deployment requirements
Use of automation tools should be considered where:
- Application changes are packaged into deployment “bundle” with clear associations between the configuration changes and application release dates to each environment
- Automation tracks all individual components that constitutes a “bundle”
- Fully automated backend process (including automated back-out of changes)
- Provides push-button controlled/approved and self-service levels of deployment process
- Logging of changes for configuration-management auditing
- Maximizes access control for PCI-DSS compliance
6.2 Deployment Automation
In addition to managing the source code repository itself, management of deployment through deployment automation that encompasses both application changes as well as system changes is considered a best practice.
Though it is conceivable that scripts could be written to accommodate all of the various types of changes to all of the possible WebSphere products and components involved in the “REGIONAL BANK A” ESB configuration, it is not recommended due to the high complexity and amount of time required, which contributes to the overall cost of maintaining homegrown deployment scripts.
This reason alone is perhaps why “REGIONAL BANK A” deployments continue to be manual in nature.
In evaluating the available tools and utilities for automation deployments for WebSphere, consider that deployment of ESB changes are generally of two types:
- Application Changes – Application changes include new message flows, new application queues, new .ear files or WTX maps, all of which have association with each other with regard to version control with the application bundle.
- System Changes. System-level changes include the applying of hot fixes, fix packs, and major-release software-version levels. They could also involve environment-configuration settings such as adding a new application ID, group access, database driver, resource-connection pooling configuration and other parameters that enable better performance and throughput. Additionally, WebSphere and Java version levels are somewhat independent of each other, though many times showing critical dependencies with each other in terms of application functionality and thus require configuration management with application bundles.
As a result of the above, it is recommended that “Regional Bank A” consider packaged products that will automate systems as well as application deployments and manage technical dependencies without the use and ongoing maintenance of deployment scripts.
Because of the complexity of the ESB configuration, such products as Rational UDeploy in conjunction with Rational Team Concert are now considered a best-of-breed product combination for managing application configurations and software distribution for complex multi-product ESB customers.
In closing, the review and recommendations above should be considered for initiating infrastructure projects that will address and close the items of key concern. Additionally, the initiation of projects for addressing future automation, performance management and growth of the ESB should also be considered in both the near future and beyond for strategic reasons, as well as for ongoing compliance and growth supportability.
Photo courtesy of Flickr contributor “Info Cash”