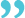by Natalie Miller | @natalieatWIS for IBM Insight Magazine
Project Description
Ohio healthcare provider Medical Mutual wanted to take on more trading partners and more easily align with government protocols, but was without the proper robust and secure infrastructure needed to support the company’s operations.“We needed to set up trading partner software and a B2B infrastructure so we could move the data inside and outside the company,” says Eleanor Danser, EDI Manager, Medical Mutual of Ohio. “The parts that we were missing were the trading partner software and the communications piece to support all the real-time protocols that are required from the ACA, which is the Affordable Care Act.
”Medical Mutual already had IBM WebSphere MQ and IBM WebSphere Message Broker, as well as IBM WebSphere Transformation Extender (TX) in its arsenal to move the company’s hundreds of daily file transfer protocol (FTP) transactions. Healthcare providers are constantly moving data and setting up connections between different industry sectors—efforts that involve securing information from providers and employers who then send out to clearinghouses and providers.
“It’s constantly moving data back and forth between different entities—from claims data, membership data, eligibility and benefit information, claims status—all the transactions that the healthcare industry uses today,” says Danser.
However, as the healthcare industry evolves, so does its need for streamlined and easy communication. Medical Mutual also realized that their current infrastructure didn’t provide the company with the necessary authentication and security. It needed a Partner Gateway solution with batch and real-time processing that could match or exceed the 20-second response window in order to stay HIPAA compliant.
Medical Mutual sought a solution to aid with the communications piece of the transaction, or the “the handshake of the data,” explains Danser. “You must build thorough and robust security and protocols built the authentication of a trading partner to be able to sign in and drop data off to our systems, or for us to be able to drop data off to their systems …. It’s the authentication and security of the process that must take place in order to move the data.”
Without the proper in-house expertise for such a project, Medical Mutual called upon TxMQ, an IBM Premier business partner and provider of systems integration, implementation, consultation and training.
Choosing a solution and assembling a team
Since Medical Mutual already had an existing infrastructure in place using IBM software, choosing an IBM solution for the missing trading partner software and the communication piece was a practical decision.
We went out and looked at various vendor options. If we went outside of IBM we would have had to change certain parts of our infrastructure, which we really didn’t want to do. So this solution allowed us to use our existing infrastructure and simply build around it and enhance it. It was very cost effective to do that..
“We went out and looked at various vendor options,” explains Danser. “If we went outside of IBM we would have had to change certain parts of our infrastructure, which we really didn’t want to do. So this solution allowed us to use our existing infrastructure and simply build around it and enhance it. It was very cost effective to do that.”
In December 2012, Danser and her team received approval to move forward with IBM WebSphere DataPower B2B Appliance XB62 — a solution widely used in the healthcare industry with the built-in trading partner setup and configurations Medical Mutual wanted to implement.
TxMQ’s experience and connections set Medical Mutual up for success
The project kicked off in early 2013 with the help of four experts from TxMQ. The TxMQ team of four worked alongside Danser’s team of four fulltime staff members from project start through the September 2013 launch of the system.
“[TxMQ] possessed the expertise we needed to support what we were trying to do,” says Danser of the TxMQ team, which consisted of an IBM WebSphere DataPower project manager, an IBM WebSphere DataPower expert, an IBM WebSphere TX translator expert, and an IBM WebSphere Message Broker expert. “They helped us with the design of the infrastructure and the layout of the project. “
The design process wrapped up in April 2013, after which implementation began. According to Danser, the TxMQ project manager was on-site in the Ohio office once a week for the first few months. The Message Broker expert was onsite for almost four months. Some of the experts, for IBM WebSphere DataPower as one example, had weekly meetings from an offsite location.
Overcoming Implementation Challenges
TxMQ stayed on until the project went live in September 2013— two-and-a-half months past Danser’s original delivery date estimate. The biggest challenge that contributed to the delay was Medical Mutual’s limited experience with the technology, which required cross-training.
“We didn’t have any expertise in-house,” explains Danser, adding that the IBM WebSphere DataPower systems and the MQFTE were the steepest parts of the learning curve. “We relied a lot on the consultants to fill that gap for us until we were up to speed. We did bring in some of the MQ training from outside, but primarily it was learning on the job, so that slowed us down quite a bit. We knew how our old infrastructure worked and this was completely different.”
Another issue that contributed to delay was the need to search and identify system-platform ownership. “Laying out ownership of the pieces … took a while, given the resources and time required,” explains Danser. “It involved trying to lay out how the new infrastructure should work and then putting the processes we had in place into that new infrastructure. We knew what we wanted it to do—it was figuring out how to do that.”
And because Danser’s team wanted the system to work the same way as the existing infrastructure, heavy customization was also needed. “There was a lot of homegrown code that went into the process,” she adds.
Project realizes cost savings, increased efficiency
Since the implementation, Medical Mutual reports real cost savings and increased efficiency. As was the goal from the beginning, the company can now more easily take on trading partners. According to Danser, the use of IBM WebSphere DataPower creates an infrastructure that greatly improves the time needed to set up those trading partner connections, including a recent connection with the Federal Exchange. Medical Mutual is now able to shorten testing with trading partners’ and move data more quickly.
“Before, it would take weeks to [take on a new partner], and now we are down to days,” says Danser.
“We’re not restricted to just the EDI transactions anymore,” she continues, explaining that Medical Mutual’s infrastructure is now not only more robust, but more flexible. “We can use XML [Management Interface] and tools like that to move data also.”
IBM WebSphere DataPower additionally moved Medical Mutual from batch processing into a real-time environment. The new system gives trading partners the ability to manage their own transactions and automates the process into a browser-based view for them, so onboarding new partners is now a faster, more scalable process.
Additionally, Medical Mutual has been able to significantly reduce transaction fees for claims data by going direct with clearinghouses or other providers. According to Danser, Medical Mutual expects an annual savings of $250,000 to $500,000 in transactional fees.
Photo courtesy of Flickr contributor Michael Roper


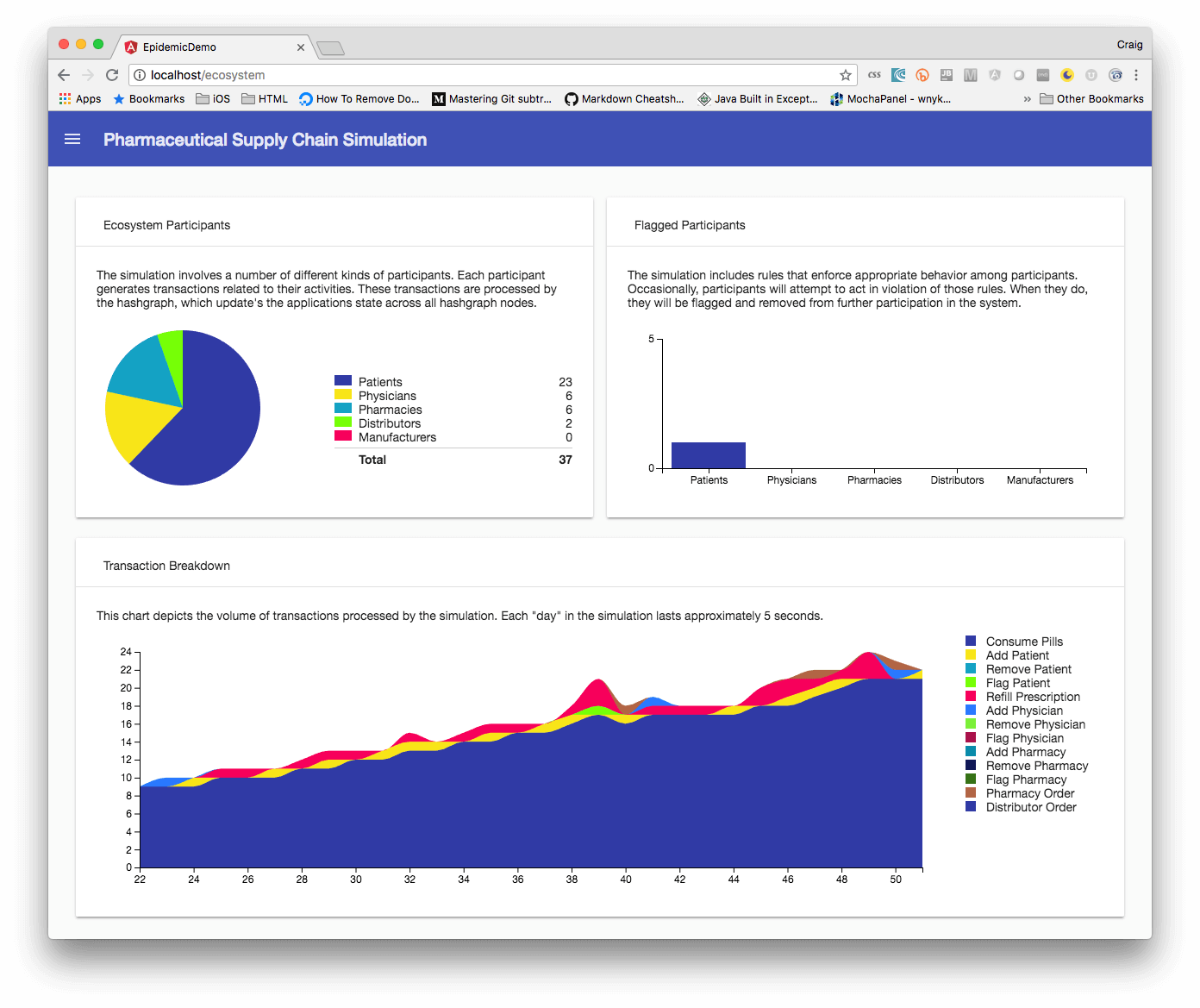
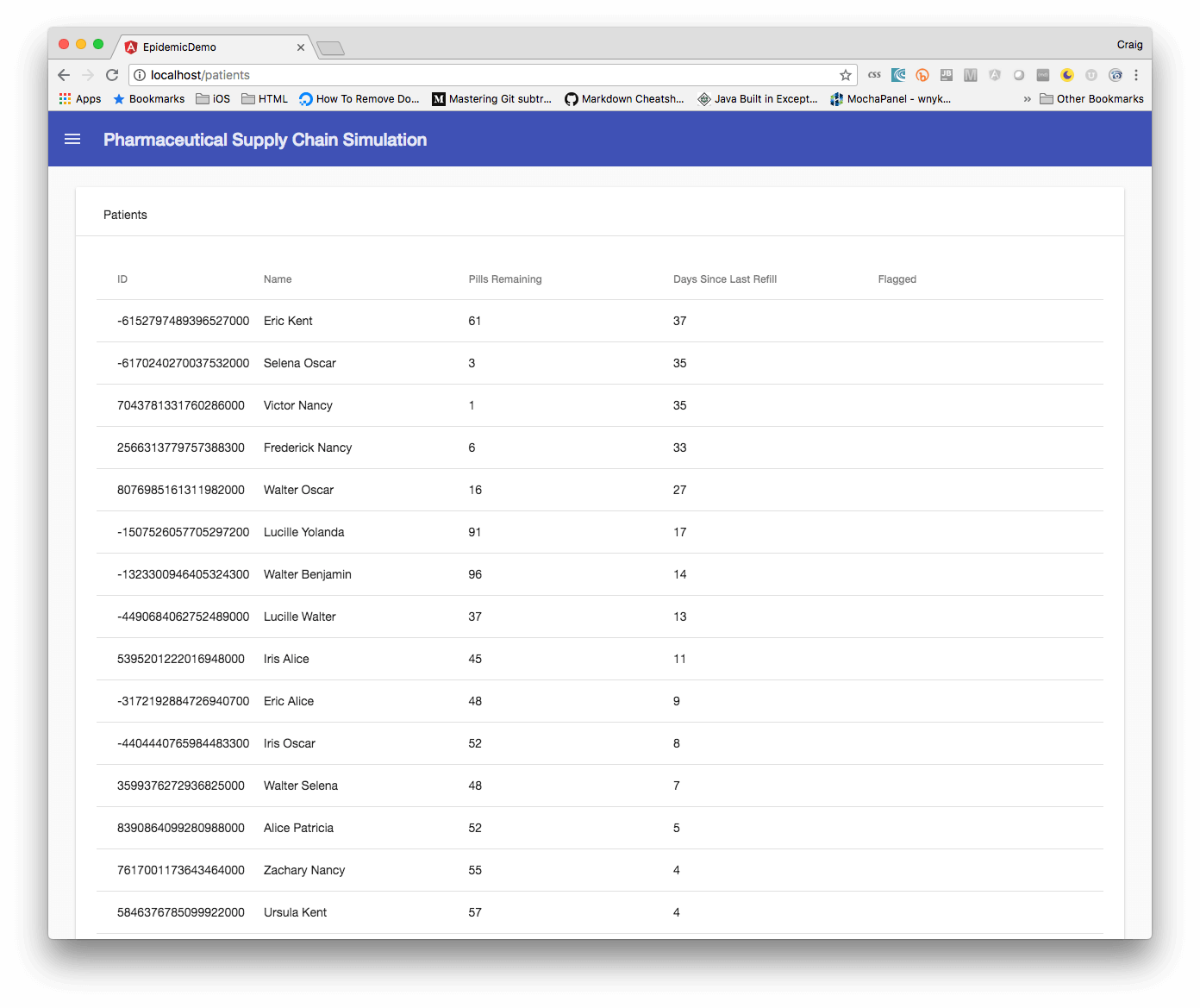
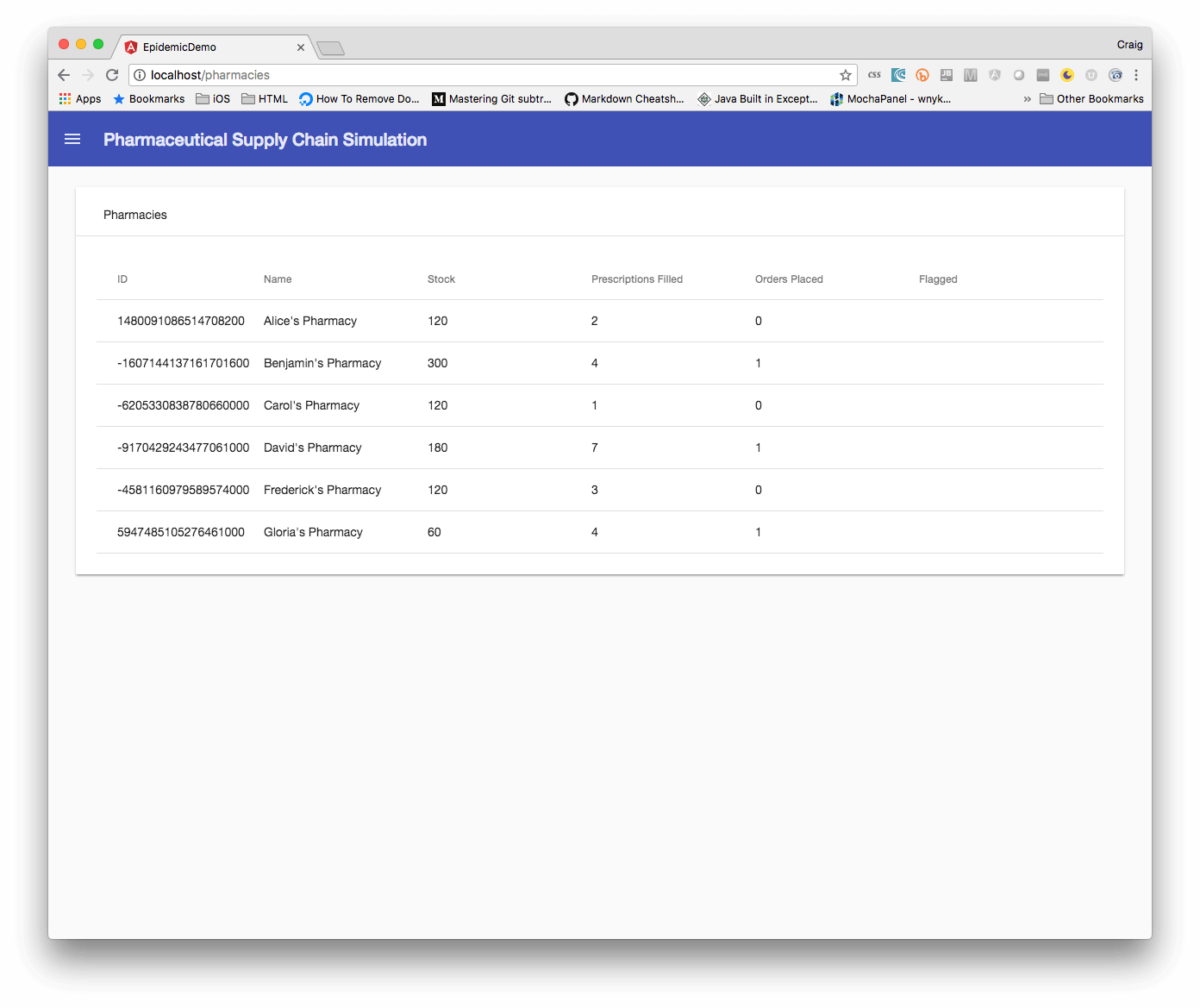

 We also wanted to make sure that the solution would support us for years to come, not just a year or two. By the time we were done, we were pretty confident with the decision that we made. Overall we feel the solution was appropriate for Medical Mutual.
We also wanted to make sure that the solution would support us for years to come, not just a year or two. By the time we were done, we were pretty confident with the decision that we made. Overall we feel the solution was appropriate for Medical Mutual.